
Feed aggregator
Is it a must to run pupbld.sql as system
Mixed version dataguard
How to call rest api which accept x-www-form-urlencoded in PL/SQL procedure in Apex
Error in pl/sql code

Oracle Is Guilty Until Proven Innocent
Received email from Technical Lead | Senior Manager for the following errors.
Error Description: 0: Invalid pool name ‘oraclePool’ while getting a database connection.
Please check for consistency of the properties files or BPML
Time of Event: 20240419141429
Workflow Id: 88867
First inclination is to check Oracle database parameters (sessions and processes) which wasted time on a wild goose chase.
I am by no mean an expert but Google is your friend.
It puzzle me how a Technical Lead | Senior Manager does not know how to Google.
LMGTFY – Let Me Google That For You for all those people who find it more convenient to bother you with their question rather than to Google it for themselves.
How to update a user defined database package in production
How to Quantize a Model with Hugging Face Quanto
This video is a hands-on step-by-step primer about how to quantize any model using Hugging Face Quanto which is a versatile pytorch quantization toolkit.
!pip install transformers==4.35.0
!pip install quanto==0.0.11
!pip install torch==2.1.1
!pip install sentencepiece==0.2.0
model_name = "google/flan-t5-small"
import sentencepiece as spm
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("google/flan-t5-small")
model = T5ForConditionalGeneration.from_pretrained("google/flan-t5-small")
input_text = "Meaning of happiness is "
input_ids = tokenizer(input_text, return_tensors="pt").input_ids
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
from helper import compute_module_sizes
module_sizes = compute_module_sizes(model)
print(f"The model size is {module_sizes[''] * 1e-9} GB")
from quanto import quantize, freeze
import torch
quantize(model, weights=torch.int8, activations=None)
freeze(model)
module_sizes = compute_module_sizes(model)
print(f"The model size is {module_sizes[''] * 1e-9} GB")
input_text = "Meaning of happiness is "
input_ids = tokenizer(input_text, return_tensors="pt").input_ids
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
How to do RAG in OpenAI GPT4 Locally with File Search
This video is a hands-on step-by-step primer about how to use RAG with Open AI File Search. OpenAI now supports RAG which means that now you can attach your own files and custom data to OpenAI assistant and talk to your documents with GPT4.
Make sure you have installed latest version of openai on your local system:
pip install openai --upgrade
also make sure to have data.txt in the same folder as your script.
How to Use LLM Function Calling Locally for Free
Function calling in AI simply means that you can call external APIs from within your AI-powered application. Whenever you read that a model can do function calling, it means that it can take a natural language query of user and convert it to a function call. Then you can execute that function call to your API endpoint to get the data, and give it to LLM as additional context and get more grounded latest response as per your application requirement.
to_char a big number insert into database become scientific notation
Explain plan estimate vs actual
Learning Azure by having fun with ChatGPT
Are you studying for an Azure certification? You may feel at some point you need a break from the dry and factual technical information. I’m in your shoes right now and I have done some experiments with ChatGPT. I’m not using it to write my text but to learn by having fun! It is very good at telling stories so why not use that for what interests me right now? Azure architecture!
In this blog post I’m going to show you how I use it, it may give you some ideas to make your learning a little more spicy!
 Prompt for preparing ChatGPT with Azure
Prompt for preparing ChatGPT with Azure
First you’ll need to prepare ChatGPT by explaining what you want. Set the framework and limit its responses otherwise it is too chatty. As I like science fiction (sci-fi), I’m interested in a futuristic story but you could choose any style you like. My first prompt and ChatGPT response is shown below:
Act as an Azure architect. You are in charge of educating me, your student, to become an Azure architect too. You will respond to my questions by using story telling to explain each concepts requested.
I want you to:
– Always tell a simple and futuristic story
– Limit the reply to 100 words
As an Azure architect, imagine Azure as a vast cosmic city. Each service is a towering skyscraper, and we, architects, design the blueprints. Let’s start with Virtual Networks. They’re like the city’s infrastructure, connecting buildings. Subnets divide areas within each building, like floors. Next, VMs are the inhabitants, residing in these skyscrapers, each serving a unique purpose. Azure Storage, a network of secure vaults, safeguards their belongings. With Azure Load Balancer as traffic controllers, the city thrives, ensuring smooth navigation. As architects of this digital metropolis, we sculpt a future where innovation soars amidst the azure skyline.
Not bad! It gives me some key components of an Azure infrastructure and makes some analogies I can easily picture in my head. With this basis, I can now be the hero of this story by asking more questions.
Build up that Azure cosmic city with ChatGPTYou can then ask questions around your area of study (mine is Azure architecture) and stay immersed into that story. For example:
What are the best practice to govern this Azure cosmic city?
In our cosmic city, governance is paramount. Azure Policy acts as the city’s constitution, ensuring compliance with regulations. Role-Based Access Control (RBAC) assigns roles to citizens, granting appropriate permissions. Azure Resource Manager templates are like city blueprints, ensuring consistency in construction. Tags label buildings for easy identification, while Azure Monitor keeps a watchful eye on city activities. With these best practices, our cosmic city thrives, ensuring order, security, and harmony amidst the azure skyline.It gives you the key elements of Azure governance by continuing its story. You can go on like this back and forth by throwing in any chapter of your course. You can focus on a specific use case as well and see how it integrates with this story:
How can I migrate my SQL Server database on-premises to this city?
Imagine your SQL Server database as a cozy cottage in the countryside. To migrate to our cosmic city, Azure, we’ll use Azure Database Migration Service, like a futuristic moving company. It carefully transports your data to Azure SQL Database, a sleek skyscraper in our city. With minimal downtime, your database seamlessly transitions to its new home, ready to thrive amidst the azure skyline. Just sit back, relax, and watch as your data becomes part of the bustling digital metropolis.How do I ensure my database is highly resilient in this cosmic city?
In our cosmic city, resilience is key. Azure offers a robust solution: Azure SQL Database with built-in redundancy, akin to a fortress with multiple layers of defense. Automatic backups act as a safety net, ensuring data is never lost. Geo-replication creates duplicates across regions, safeguarding against disasters. With Azure SQL Database’s high availability and disaster recovery features, your database thrives amidst the azure skyline, resilient against any digital storm.I don’t know if it works for you but I find it fascinating I can make ChatGPT talk endlessly and respond to any questions I have about Azure in a sci-fi story!
Dive into an Azure componentAs usual with ChatGPT you need to drive the discussion to get the most of it. Let’s see what it has to say about Azure AD (I use the legacy terminology as ChatGPT v3.5 doesn’t know yet Microsoft Entra ID):
What and where would be the Azure AD in this city?
In our bustling city, Azure AD is the central hub, akin to City Hall. It’s where identities are registered, like citizens in our digital society. Located at the heart of the city, Azure AD ensures secure access to every digital service and resource, much like City Hall grants access to essential services. From authentication to authorization, Azure AD governs the city’s digital identities, ensuring a seamless and secure experience for all inhabitants amidst the azure skyline.How would Azure AD conditional access be implemented in this city?
In our city, Azure AD Conditional Access acts as the city’s security checkpoints. Picture futuristic gates at key entry points, only granting access to authorized individuals based on specific conditions. Want to enter the financial district skyscraper? You’ll need more than just a pass; perhaps a biometric scan during business hours. Conditional Access ensures only the right people, with the right permissions, access sensitive areas of our digital city. It’s our shield against cyber threats amidst the azure skyline, ensuring a safe and secure digital environment for all inhabitants.How would I connect from my Active Directory in the countryside to this Azure AD in the cloud?
In the countryside, your Active Directory (AD) is like a quaint village square, bustling with local identities. To connect to Azure AD in our cosmic cloud city, envision a digital bridge spanning the distance between village and skyline. Azure AD Connect is your trusty guide, seamlessly synchronizing identities from countryside AD to Azure AD. With this bridge in place, villagers can access digital services in the cloud using their familiar countryside credentials. Just like that, the countryside becomes an integral part of our digital metropolis, united under the azure skyline.You can then piece by piece for each component create a complete city in the countryside (OnPrem) and in the cloud and illustrate their interaction. We could completely gamify this! SimCity anyone?
LimitationsSome general concepts are more difficult to put into a visual story as for example the Microsoft Cloud Adoption Framework:
What would be the Microsoft Cloud Adoption Framework for Azure in this city?
In our dynamic metropolis, the Microsoft Cloud Adoption Framework for Azure is our roadmap to success. Like a futuristic GPS, it guides us through the twists and turns of digital transformation. Envisioning helps us set our destination, planning ensures we choose the best route, and readiness prepares us for the journey ahead. Migration helps us seamlessly transition, while innovation propels us forward. With governance as our compass and optimization as our fuel, we navigate the ever-changing landscape, building a future where our digital city thrives amidst the azure skyline. Ready to embark on this transformative journey?I don’t find it fantastic as we recognize the empty blabbering of ChatGPT. We would need to be more specific to get something more interesting.
Wrap upYou can see how by relaxing from your studies, you can still continue to learn by having fun in an imaginary world. You could totally convert all this into visual notes that will help you when you renew your certifications. That is something I’m starting to explore.
This is just a glimpse of how you could use ChatGPT in your journey to learn Azure or anything else. Brainstorm any concept, service or component you are learning and see how it integrates into a visual story to get a high-level picture. Let me know if your are using ChatGPT that way for learning and what is the world you are building for it!
L’article Learning Azure by having fun with ChatGPT est apparu en premier sur dbi Blog.
Embedding Machine Learning Models in the Oracle Database: Create an ONNX model
This post is the first of a three-part series where I’m going to show you how to use pre-configured […]
The post Embedding Machine Learning Models in the Oracle Database: Create an ONNX model appeared first on DBASolved.
Local LLM RAG with Unstructured and LangChain [Structured JSON]
Freddie Starr Ate My File ! Finding out exactly what the Oracle Filewatcher is up to
As useful as they undoubtedly are, any use of a DBMS_SCHEDULER File Watchers in Oracle is likely to involve a number of moving parts.
This can make trying to track down issues feel a bit like being on a hamster wheel.
Fortunately, you can easily find out just exactly what the filewatcher is up to, if you know where to look …
I’ve got a procedure to populate a table with details of any arriving file.
create table incoming_files(
destination VARCHAR2(4000),
directory_path VARCHAR2(4000),
actual_file_name VARCHAR2(4000),
file_size NUMBER,
file_timestamp TIMESTAMP WITH TIME ZONE)
/
create or replace procedure save_incoming_file( i_result sys.scheduler_filewatcher_result)
as
begin
insert into incoming_files(
destination,
directory_path,
actual_file_name,
file_size,
file_timestamp)
values(
i_result.destination,
i_result.directory_path,
i_result.actual_file_name,
i_result.file_size,
i_result.file_timestamp);
end;
/
The filewatcher and associated objects that will invoke this procedure are :
begin
dbms_credential.create_credential
(
credential_name => 'starr',
username => 'fstarr',
password => 'some-complex-password'
);
end;
/
begin
dbms_scheduler.create_file_watcher(
file_watcher_name => 'freddie',
directory_path => '/u01/app/upload_files',
file_name => '*.txt',
credential_name => 'starr',
enabled => false,
comments => 'Feeling peckish');
end;
/
begin
dbms_scheduler.create_program(
program_name => 'snack_prog',
program_type => 'stored_procedure',
program_action => 'save_incoming_file',
number_of_arguments => 1,
enabled => false);
-- need to make sure this program can see the message sent by the filewatcher...
dbms_scheduler.define_metadata_argument(
program_name => 'snack_prog',
metadata_attribute => 'event_message',
argument_position => 1);
-- Create a job that links the filewatcher to the program...
dbms_scheduler.create_job(
job_name => 'snack_job',
program_name => 'snack_prog',
event_condition => null,
queue_spec => 'freddie',
auto_drop => false,
enabled => false);
end;
/
The relevant components have been enabled :
begin
dbms_scheduler.enable('freddie');
dbms_scheduler.enable('snack_prog');
dbms_scheduler.enable('snack_job');
end;
/
… and – connected on the os as fstarr – I’ve dropped a file into the directory…
echo 'Squeak!' >/u01/app/upload_files/hamster.txtFile watchers are initiated by a scheduled run of the SYS FILE_WATCHER job.
The logging_level value determines whether or not the executions of this job will be available in the *_SCHEDULER_JOB_RUN_DETAILS views.
select program_name, schedule_name,
job_class, logging_level
from dba_scheduler_jobs
where owner = 'SYS'
and job_name = 'FILE_WATCHER'
/
PROGRAM_NAME SCHEDULE_NAME JOB_CLASS LOGGING_LEVEL
-------------------- ------------------------- ----------------------------------- ---------------
FILE_WATCHER_PROGRAM FILE_WATCHER_SCHEDULE SCHED$_LOG_ON_ERRORS_CLASS FULL
If the logging_level is set to OFF (which appears to be the default in 19c), you can enable it by connecting as SYSDBA and running :
begin
dbms_scheduler.set_attribute('FILE_WATCHER', 'logging_level', dbms_scheduler.logging_full);
end;
/
The job is assigned the FILE_WATCHER_SCHEDULE, which runs every 10 minutes by default. To check the current settings :
select repeat_interval
from dba_scheduler_schedules
where schedule_name = 'FILE_WATCHER_SCHEDULE'
/
REPEAT_INTERVAL
------------------------------
FREQ=MINUTELY;INTERVAL=10
The thing is, there are times when the SYS.FILE_WATCHER seems to slope off for a tea-break. So, if you’re wondering why your file has not been processed yet, it’s handy to be able to check if this job has run when you expected it to.
In this case, as logging is enabled, we can do just that :
select log_id, log_date, instance_id, req_start_date, actual_start_date
from dba_scheduler_job_run_details
where owner = 'SYS'
and job_name = 'FILE_WATCHER'
and log_date >= sysdate - (1/24)
order by log_date desc
/
LOG_ID LOG_DATE INSTANCE_ID REQ_START_DATE ACTUAL_START_DATE
------- ----------------------------------- ----------- ------------------------------------------ ------------------------------------------
1282 13-APR-24 14.50.47.326358000 +01:00 1 13-APR-24 14.50.47.000000000 EUROPE/LONDON 13-APR-24 14.50.47.091753000 EUROPE/LONDON
1274 13-APR-24 14.40.47.512172000 +01:00 1 13-APR-24 14.40.47.000000000 EUROPE/LONDON 13-APR-24 14.40.47.075846000 EUROPE/LONDON
1260 13-APR-24 14.30.47.301176000 +01:00 1 13-APR-24 14.30.47.000000000 EUROPE/LONDON 13-APR-24 14.30.47.048977000 EUROPE/LONDON
1248 13-APR-24 14.20.47.941210000 +01:00 1 13-APR-24 14.20.47.000000000 EUROPE/LONDON 13-APR-24 14.20.47.127769000 EUROPE/LONDON
1212 13-APR-24 14.10.48.480193000 +01:00 1 13-APR-24 14.10.47.000000000 EUROPE/LONDON 13-APR-24 14.10.47.153032000 EUROPE/LONDON
1172 13-APR-24 14.00.50.676270000 +01:00 1 13-APR-24 14.00.47.000000000 EUROPE/LONDON 13-APR-24 14.00.47.111936000 EUROPE/LONDON
6 rows selected.
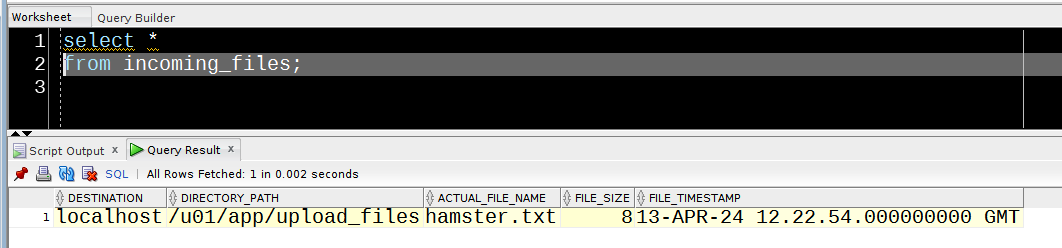
Even if the SYS.FILE_WATCHER is not logging, when it does run, any files being watched for are added to a queue, the contents of which can be found in SCHEDULER_FILEWATCHER_QT.
This query will get you the really useful details of what your filewatcher has been up to :
select
t.step_no,
treat( t.user_data as sys.scheduler_filewatcher_result).actual_file_name as filename,
treat( t.user_data as sys.scheduler_filewatcher_result).file_size as file_size,
treat( t.user_data as sys.scheduler_filewatcher_result).file_timestamp as file_ts,
t.enq_time,
x.name as filewatcher,
x.requested_file_name as search_pattern,
x.credential_name as credential_name
from sys.scheduler_filewatcher_qt t,
table(t.user_data.matching_requests) x
where enq_time > trunc(sysdate)
order by enq_time
/
STEP_NO FILENAME FILE_SIZE FILE_TS ENQ_TIME FILEWATCHER SEARCH_PATTERN CREDENTIAL_NAME
---------- --------------- ---------- -------------------------------- ---------------------------- --------------- --------------- ---------------
0 hamster.txt 8 13-APR-24 12.06.58.000000000 GMT 13-APR-24 12.21.31.746338000 FREDDIE *.txt STARR
Happily, in this case, our furry friend has avoided the Grim Squaker…
NOTE – No hamsters were harmed in the writing of this post.
Oracle OEM Read Only Access
With great power comes great responsibility.
Reference: https://en.wikipedia.org/wiki/With_great_power_comes_great_responsibility
On boarding 4 Database Consultants and they have request access to OEM. Sharing SYSMAN password with every DBA is not a good idea and also difficult to determined who messed up.
Here are 2 articles and I favor Doc ID 2180307.1 based on last update and contains screenshots.
OEM 13c How To Create an Administrator with Read Only Access (Doc ID 2925232.1)
Enterprise Manager Base Platform – Version 13.4.0.0.0 and later
Last Update: Feb 1, 2023
EM 13c : How to Create an EM Administrator with Read Only Access to the Performance Pages of a Database Target? (Doc ID 2180307.1)
Enterprise Manager for Oracle Database – Version 13.1.1.0.0 and later
Last Update: May 9, 2023
Would have been nice to have emcli script to do this but beggars cannot be choosers.
Monitor Elasticsearch Cluster with Zabbix
Setting up Zabbix monitoring over an Elasticsearch cluster is quiet easy as it does not require an agent install. As a matter a fact, the official template uses the Elastic REST API. Zabbix server itself will trigger these requests.
In this blog post, I will quick explain how to setup Elasticsearch cluster, then how easy the Zabbix setup is and list possible issues you might encounter.
Elastic Cluster SetupI will not go too much in detail as David covered already many topics around ELK. Anyway, would you need any help to install, tune or monitor your ELK cluster fell free to contact us.
My 3 virtual machines are provisioned with YaK on OCI. Then, I install the rpm on all 3 nodes.
After starting first node service, I am generating an enrollment token with this command:
/usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -node
This return a long string which I will need to pass on node 2 and 3 of the cluster (before starting anything):
/usr/share/elasticsearch/bin/elasticsearch-reconfigure-node --enrollment-token <...>
Output will look like that:
This node will be reconfigured to join an existing cluster, using the enrollment token that you provided.
This operation will overwrite the existing configuration. Specifically:
- Security auto configuration will be removed from elasticsearch.yml
- The [certs] config directory will be removed
- Security auto configuration related secure settings will be removed from the elasticsearch.keystore
Do you want to continue with the reconfiguration process [y/N]
After confirming with a y, we are almost ready to start. First, we must update ES configuration file (ie. /etc/elasticsearch/elasticsearch.yml).
- Add IP of first node (only for first boot strapped) in
cluster.initial_master_nodes: ["10.0.0.x"] - Set listening IP of the inter-node trafic (to do on node 1 as well):
transport.host: 0.0.0.0 - Set list of master eligible nodes:
discovery.seed_hosts: ["10.0.0.x:9300"]
Now, we are ready to start node 2 and 3.
Let’s check the health of our cluster:
curl -s https://localhost:9200/_cluster/health -k -u elastic:password | jq
If you forgot elastic password, you can reset it with this command:
/usr/share/elasticsearch/bin/elasticsearch-reset-password -u elastic
With latest Elasticsearch release, security has drastically increased as SSL communication became the standard. Nevertheless, default MACROS values of the template did not. Thus, we have to customize the followings:
- {$ELASTICSEARCH.USERNAME} to elastic
- {$ELASTICSEARCH.PASSWORD} to its password
- {$ELASTICSEARCH.SCHEME} to https
If SELinux is enabled on your Zabbix server, you will need to allow zabbix_server process to send network request. Following command achieves this:
setsebool zabbix_can_network 1
Next, we can create a host in Zabbix UI like that:
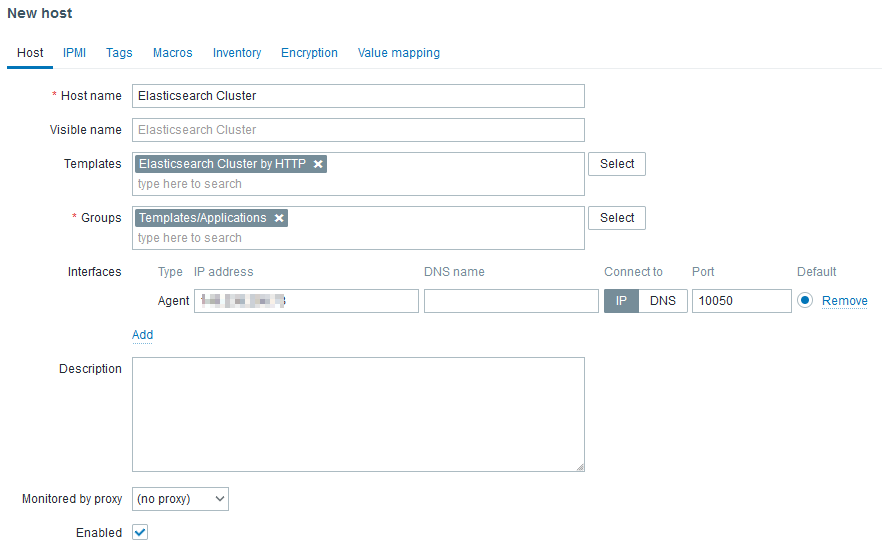
The Agent interface is required but will not be used to reach any agent as there are not agent based (passive or active) checks in the linked template. However, http checks uses HOST.CONN MACRO in the URLs. Ideally, the IP should be a virtual IP or a load balanced IP.
Don’t forget to set the MACROS:
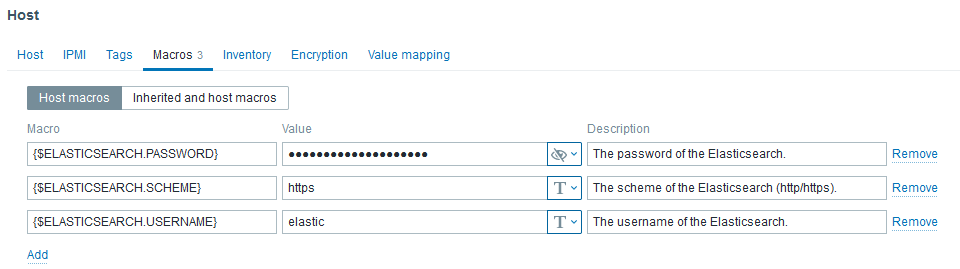
After few minutes, and once nodes discovery ran, you should see something like that:
What will happen if one node stops? On Problems tab of Zabbix UI:

After few seconds, I noticed that ES: Health is YELLOW gets resolved on its own. Why? Because shards are re-balanced across running servers.
I confirm this by graphing Number of unassigned shards:
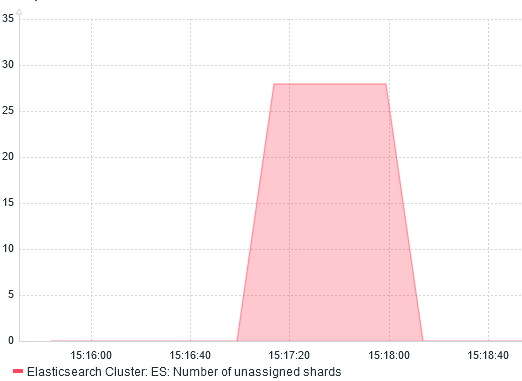
We can also see the re-balancing with the network traffic monitoring:
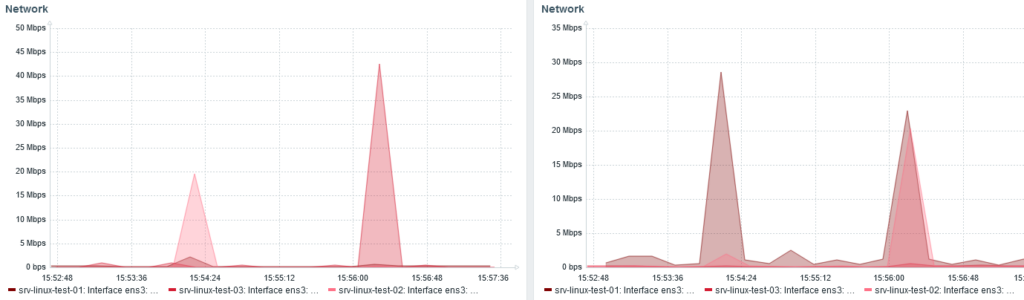 Received bytes on the left. Sent on the right.
Received bytes on the left. Sent on the right.
Around 15:24, I stopped node 3 and shards were redistributed from node 1 and 2.
When node 3 start, at 15:56, we can see node 1 and 2 (20 Mbps each) send back shards to node 3 (40 Mbps received).
ConclusionWhatever the monitoring tool you are using, it always help to understand what is happening behind the scene.
L’article Monitor Elasticsearch Cluster with Zabbix est apparu en premier sur dbi Blog.
Power BI Report Server: unable to publish a PBIX report
I installed a complete new Power BI Report Server. The server had several network interfaces to be part of several subdomains. In order to access the Power BI Report Server web portal from the different subdomains I defined 3 different HTTPS URL’s in the configuration file and a certificate binding. I used as well a specific active directory service account to start the service. I restarted my Power BI Report Server service checking that the URL reservations were done correctly. I knew that in the past this part could be a source of problems.
Everything seemed to be OK. I tested the accessibility to the Power BI Report Server web portal from the different sub-nets clients and everything was fine.
The next test was the upload of a Power BI report to the web portal. Of course I was sure, having a reports developed with Power BI Desktop RS.
Error raisedAn error was raised when uploading a Power BI report in the web portal.
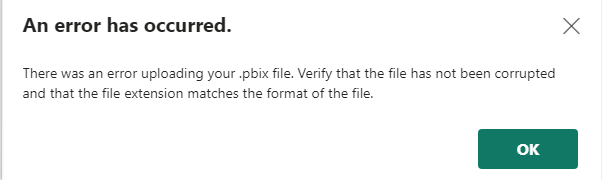
Trying to publish the report from Power BI Desktop RS was failing as well.
 Troubleshouting
Troubleshouting
Report Server log analysis:
I started to analyze the Power BI Report Server logs. For a standard installation they are located in
C:\Program Files\Microsoft Power BI Report Server\PBIRS\LogFiles
In the last RSPowerBI_yyyy_mm_dd_hh_mi_ss.log file written I could find the following error:
Could not start PBIXSystem.Reflection.TargetInvocationException: Exception has been thrown by the target of an invocation. ---> System.Net.HttpListenerException: Access is denied
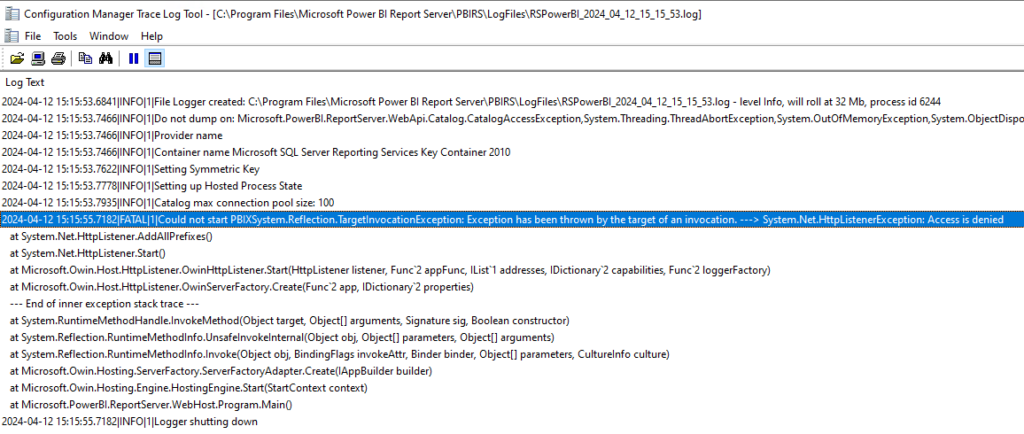
The error showing an Access denied, the first reaction was to put the service account I used to start the Power BI Report Server in the local Administrators group.
I restarted the service and tried again the publishing of the Power BI report. It worked without issue.
Well, I had a solution, but the it wasn’t an acceptable one. A application service account should not be local admin of a server, it would be a security breach and is not permitted by the security governance.
Based on the information contained in the error message, I could find that is was related to URL reservation, but from the configuration steps, I could not notice any issues.
I analyzed than the list of the reserved URL on the server. Run the following command with elevated permissions to get the list of URL reservation on the server:
Netsh http show urlacl
List of URL reservation found for the user NT SERVICE\PowerBIReportServer:
Reserved URL : http://+:8083/
User: NT SERVICE\PowerBIReportServer
Listen: Yes
Delegate: No
SDDL: D:(A;;GX;;;S-1-5-80-1730998386-2757299892-37364343-1607169425-3512908663)
Reserved URL : https://sub1.domain.com:443/ReportServerPBIRS/
User: NT SERVICE\PowerBIReportServer
Listen: Yes
Delegate: No
SDDL: D:(A;;GX;;;S-1-5-80-1730998386-2757299892-37364343-1607169425-3512908663)
Reserved URL : https://sub2.domain.com:443/ReportServerPBIRS/
User: NT SERVICE\PowerBIReportServer
Listen: Yes
Delegate: No
SDDL: D:(A;;GX;;;S-1-5-80-1730998386-2757299892-37364343-1607169425-3512908663)
Reserved URL : https://servername.domain.com.ch:443/PowerBI/
User: NT SERVICE\PowerBIReportServer
Listen: Yes
Delegate: No
SDDL: D:(A;;GX;;;S-1-5-80-1730998386-2757299892-37364343-1607169425-3512908663)
Reserved URL : https://servername.domain.com.ch:443/wopi/
User: NT SERVICE\PowerBIReportServer
Listen: Yes
Delegate: No
SDDL: D:(A;;GX;;;S-1-5-80-1730998386-2757299892-37364343-1607169425-3512908663)
Reserved URL : https://sub1.domain.com:443/ReportsPBIRS/
User: NT SERVICE\PowerBIReportServer
Listen: Yes
Delegate: No
SDDL: D:(A;;GX;;;S-1-5-80-1730998386-2757299892-37364343-1607169425-3512908663)
Reserved URL : https://sub2.domain.com:443/ReportsPBIRS/
User: NT SERVICE\PowerBIReportServer
Listen: Yes
Delegate: No
SDDL: D:(A;;GX;;;S-1-5-80-1730998386-2757299892-37364343-1607169425-3512908663)
Reserved URL : https://servername.domain.com.ch:443/ReportsPBIRS/
User: NT SERVICE\PowerBIReportServer
Listen: Yes
Delegate: No
SDDL: D:(A;;GX;;;S-1-5-80-1730998386-2757299892-37364343-1607169425-3512908663)
Checking the list I could find:
- the 3 URL’s reserved fro the web service containing the virtual directory I defined ReportServerPBIRS
- the 3 URL’s reserved fro the web portal containing the virtual directory I defined ReportsPBIRS
But I noticed that only 1 URL was reserved for the virtual directories PowerBI and wopi containing the servername.
The 2 others with the subdomains were missing.
SolutionI decided to reserve the URL for PowerBI and wopi virtual directory on the 2 subdomains running the following command with elevated permissions.
Be sure that the SDDL ID used is the one you find in the rsreportserver.config file.
netsh http add urlacl URL=sub1.domain.com:443/PowerBI/ user="NT SERVICE\SQLServerReportingServices" SDDL="D:(A;;GX;;;S-1-5-80-1730998386-2757299892-37364343-1607169425-3512908663)"
netsh http add urlacl URL=sub2.domain.com:443/PowerBI/ user="NT SERVICE\SQLServerReportingServices" SDDL="D:(A;;GX;;;S-1-5-80-1730998386-2757299892-37364343-1607169425-3512908663)"
netsh http add urlacl URL=sub1.domain.com:443/wopi/ user="NT SERVICE\SQLServerReportingServices" SDDL="D:(A;;GX;;;S-1-5-80-1730998386-2757299892-37364343-1607169425-3512908663)"
netsh http add urlacl URL=sub2.domain.com:443/wopi// user="NT SERVICE\SQLServerReportingServices" SDDL="D:(A;;GX;;;S-1-5-80-1730998386-2757299892-37364343-1607169425-3512908663)"
Restart the Power BI Report Server service
You can notice that the error in the latest RSPowerBI_yyyy_mm_dd_hh_mi_ss.log file desappeared.
I tested the publishing of a Power BI report again, and it worked.
I hope that this reading has helped to solve your problem.
L’article Power BI Report Server: unable to publish a PBIX report est apparu en premier sur dbi Blog.
Configuring Shared Global Area (SGA) in a Multitenant Database with a PeopleSoft Pluggable Database (PDB)
I have been working on a PeopleSoft Financials application that we have converted from a stand-alone database to be the only pluggable database (PDB) in an Oracle 19c container database (CDB). We have been getting shared pool errors in the PDB that lead to ORA-4031 errors in the PeopleSoft application.
I have written a longer version of this article on my Oracle blog, but here are the main points.
SGA Management with a Parse Intensive System (PeopleSoft).PeopleSoft systems dynamically generate lots of non-shareable SQL code. This leads to lots of parse and consumes more shared pool. ASMM can respond by shrinking the buffer cache and growing the shared pool. However, this can lead to more physical I/O and degrade performance and it is not beneficial for the database to cache dynamic SQL statements that are not going to be executed again. Other parse-intensive systems can also exhibit this behaviour.
In PeopleSoft, I normally set DB_CACHE_SIZE and SHARED_POOL_SIZE to minimum values to stop ASMM shuffling too far in either direction. With a large SGA, moving memory between these pools can become a performance problem in its own right.
We removed SHARED_POOL_SIZE, DB_CACHE_SIZE and SGA_MIN_SIZE settings from the PDB. The only SGA parameters set at PDB level are SGA_TARGET and INMEMORY_SIZE.
SHARED_POOL_SIZE and DB_CACHE_SIZE are set as I usually would for PeopleSoft, but at CDB level to guarantee a minimum buffer cache size.
This is straightforward when there is only one PDB in the CDB. I have yet to see what happens when I have another active PDB with a non-PeopleSoft system and a different kind of workload that puts less stress on the shared pool and more on the buffer cache.
Initialisation Parameters- SGA_TARGET "specifies the total size of all SGA components". Use this parameter to control the memory usage of each PDB. The setting at CDB must be at least the sum of the settings for each PDB.
- Recommendations:
- Use only this parameter at PDB level to manage the memory consumption of the PDB.
- In a CDB with only a single PDB, set SGA_TARGET to the same value at CDB and PDB levels.
- Therefore, where there are multiple PDBs, SGA_TARGET at CDB level should be set to the sum of the setting for each PDB. However, I haven't tested this yet.
- There is no recommendation to reserve SGA for use by the CDB only, nor in my experience is there any need so to do.
- SHARED_POOL_SIZE sets the minimum amount of shared memory reserved to the shared pool. It can optionally be set in a PDB.
- Recommendation: However, do not set SHARED_POOL_SIZE at PDB level. It can be set at CDB level.
- DB_CACHE_SIZE sets the minimum amount of shared memory reserved to the buffer cache. It can optionally be set in a PDB.
- Recommendation: However, do not set DB_CACHE_SIZE at PDB level. It can be set at CDB level.
- SGA_MIN_SIZE has no effect at CDB level. It can be set at PDB level at up to half of the manageable SGA
- Recommendation: However, do not set SGA_MIN_SIZE.
- INMEMORY_SIZE: If you are using in-memory query, this must be set at CDB level in order to reserve memory for the in-memory store. The parameter defaults to 0, in which case in-memory query is not available. The in-memory pool is not managed by Automatic Shared Memory Management (ASMM), but it does count toward the total SGA used in SGA_TARGET.
- Recommendation: Therefore it must also be set in the PDB where in-memory is being used, otherwise we found(contrary to the documetntation) that the parameter defaults to 0, and in-memory query will be disabled in that PDB.
- A-04031 on Multitenant Database with Excessive Amounts of KGLH0 and / or SQLA Memory and Parameter SHARED_POOL_SIZE or SGA_MIN_SIZE Set at the PDB Level (Doc ID 2590172.1) – December 2022, Updated April 2023
- This one says “Remove the PDB-level SHARED_POOL_SIZE and/or SGA_MIN_SIZE initialization parameters. The only SGA memory sizing parameter that Oracle recommends setting at the PDB level is SGA_TARGET.”
- About memory configuration parameter on each PDBs (Doc ID 2655314.1) – Nov 2023
- “As a best practice, please do not to set SHARED_POOL_SIZE and DB_CACHE_SIZE on each PDBs and please manage automatically by setting SGA_TARGET.”
- "This best practice is confirmed by development in Bug 30692720"
- Bug 30692720 discusses how the parameters are validated. Eg. "Sum(PDB sga size) > CDB sga size"
- Bug 34079542: "Unset sga_min_size parameter in PDB."